| < 1. Introduction | 1.2 A Brief History Of Statistical Learning > |
💡 학습 팁: 조금 더 쉽고 재미있게 공부하고 싶으신가요? 이 페이지는 중학생도 이해할 수 있는 친절한 ‘쉬운 해설판’입니다! 영어 원문을 문장 단위로 꼼꼼하게 번역한 느낌을 원하신다면 📖 직역본 보기 메뉴를 활용하세요!
An Overview of Statistical Learning
통계적 학습 개요 (로봇은 어떻게 세상을 배우는가?)
Statistical learning refers to a vast set of tools for understanding data. 우리가 입이 마르고 닳도록 외치는 ‘통계적 학습(Statistical learning)’ 이라는 단어는, 겉보기엔 그럴싸하지만 사실 까보면 미친 듯이 쏟아지는 방대한 데이터를 ‘말귀 알아먹고 이해하기 위해’ 쓰는 거대한 삽질용 공구함 세트를 부르는 말입니다.
These tools can be classified as supervised or unsupervised. 이 거대한 공구함에는 딱 두 종류의 연장만 들어있습니다. 친절한 정답 선생님이 붙어있는 ‘지도 학습(supervised)’ 무기들과, 선생님 없이 알아서 뒹굴어야 하는 ‘비지도 학습(unsupervised)’ 무기들이죠.
Broadly speaking, supervised statistical learning involves building a statistical model for predicting, or estimating, an output based on one or more inputs. 크게 한마디로 요약하자면, ‘지도 학습(선생님이 있는 학습)’은 우리가 던져주는 하나 이상의 힌트(입력) 들을 보고 기계가 필사적으로 정답(출력) 을 때려 맞추거나(예측) 값을 추론해 내도록 수학적 그물을 짜는(모델을 짓는) 노가다 작업입니다.
Problems of this nature occur in fields as diverse as business, medicine, astrophysics, and public policy. 아니 이런 게 어디 쓰이냐고요? 회사 매출 찍기(비즈니스), 암세포 찾기(의료), 우주의 나이 맞추기(천체 물리학), 심지어 다음번 대통령 선거 예측하기(공공 정책)까지 세상이 돌아가는 온갖 빡센 분야에서 이 기계들이 이미 스머프처럼 일하고 있습니다.
With unsupervised statistical learning, there are inputs but no supervising output; nevertheless we can learn relationships and structure from such data. 반대로 ‘비지도 학습(방목형 학습)’은 힌트(입력)만 던져주고 정답(출력)은 잃어버려서 옆에서 지도해 줄 선생님이 없는 막장 상황입니다. 그럼에도 불구하고 기계들은 자기들끼리 “어? 이 데이터들끼리 대충 끼리끼리 뭉치는데?” 하면서 데이터 바닥의 숨겨진 뼈대(구조)와 은밀한 관계망을 어떻게든 기어코 찾아내고 맙니다.
To provide an illustration of some applications of statistical learning, we briefly discuss three real-world data sets that are considered in this book. 도대체 이 통계적 학습이 현실에서 어떻게 사람들을 도우며(응용) 쓰이는지 입증하기 위해, 우리가 이 책을 끝날 때까지 뼈를 깎으며 뜯어먹을 3가지 진짜 리얼 현실 데이터들의 썰을 짧게 풀어보겠습니다.
Wage Data (임금 데이터: 내 월급은 누가 결정하는가?)
In this application (which we refer to as the Wage data set throughout this book), we examine a number of factors that relate to wages for a group of men from the Atlantic region of the United States.
(이 책에서 주야장천 Wage 데이터셋이라고 부를) 첫 번째 장난감은 미국 대서양 한구석에 사는 아저씨 집단을 데려다가 “대체 무슨 이유로 니들 남성들의 지갑 두께(임금)가 이따구로 차이 나는가?”를 탈탈 털어본 조사 기록입니다.
In particular, we wish to understand the association between an employee’s age and education, as well as the calendar year, on his wage.
특히나 우리는 직장인의 ‘나이(age)’ 와 가방끈 길이(‘교육, education’), 그리고 달력의 ‘연도(year)’ 가 과연 그의 ‘월급봉투 두께(wage)’ 랑 어떤 끈적한 관계(연관성)를 맺고 있는지 그 속셈을 까발리고 싶습니다.
Consider, for example, the left-hand panel of Figure 1.1, which displays wage versus age for each of the individuals in the data set.
백문이 불여일견, 그림 1.1의 맨 왼쪽 도화지를 구경해 보시죠. 조사받은 동네 아저씨들 한 명 한 명을 허공에 점으로 찍어서 가로축은 나이(age), 세로축은 월급(wage)으로 그려본 겁니다.
There is evidence that wage increases with age but then decreases again after approximately age 60.
딱 봐도 그림상에 충격적인 증거가 보입니다. 짬바가 차면서 월급이 나이와 함께 우상향으로 치솟다가, 슬프게도 대략 60세를 넘기는 순간부터 훅 꺾여서 다시 미끄럼틀을 타듯 감소하죠.
The blue line, which provides an estimate of the average wage for a given age, makes this trend clearer.
그 복잡한 점들 한가운데를 뚫고 지나가는 저 ‘파란색 지렁이 선’이 바로 특정 나이대별로 “한 이 정도 받겠네” 하고 어림잡은 평균 월급 선(추정치)인데, 이 인생의 슬픈 곡선(추세)을 아주 뼈때리게 명확히 보여줍니다.
Given an employee’s age, we can use this curve to predict his wage.
우리는 어떤 새로운 아저씨가 “나 몇 살이게~” 하고 나이만 던져줘도, 저 파란 곡선에 대입해서 “그럼 아재 월급은 대충 이쯤이겠구먼!” 하고 족집게처럼 예측을 선사할 수 있습니다.
However, it is also clear from Figure 1.1 that there is a significant amount of variability associated with this average value, and so age alone is unlikely to provide an accurate prediction of a particular man’s wage.
하지만 잠시만요! 그림 1.1 왼쪽을 다시 째려보면, 파란 선 위아래로 점들이 마치 폭탄 맞은 것처럼 미친 듯이 흩뿌려져(엄청난 변동성) 있는 게 보일 겁니다. 그 말인즉슨, 꼴랑 나이 한 줄만 띡 듣고 그 아저씨의 실제 월급이 얼마인지 칼같이 소수점까지 맞추기(정확한 예측)엔 턱없이 불가능(가망 없음)하다는 뜻입니다.


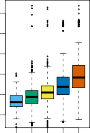
FIGURE 1.1. Wage data, which contains income survey information for men from the central Atlantic region of the United States. Left: wage as a function of age. On average, wage increases with age until about 60 years of age, at which point it begins to decline. Center: wage as a function of year. There is a slow but steady increase of approximately $10,000 in the average wage between 2003 and 2009. Right: Boxplots displaying wage as a function of education, with 1 indicating the lowest level (no high school diploma) and 5 the highest level (an advanced graduate degree). On average, wage increases with the level of education.
그림 1.1. (이 불쌍한 임금 데이터는 미국 중부 대서양 아재들의 처절한 소득 털이 정보입니다.) (왼쪽 도화지): 나이에 따른 월급의 운명. 평균적으로 월급은 60살 환갑이 될 때까지 쭉쭉 오르다가 은퇴 버프가 꺼지면서 내리막길을 걷습니다. (가운데 도화지): 연도에 따른 월급 방어전. 2003년에서 2009년 사이에 물가 덕분인지 평균 월급이 한 천만 원 대략 느릿느릿 오르긴 합니다. (오른쪽 도화지): 대망의 가방끈 길이에 따른 상자 그림. 1번은 고졸도 못 뗀 바닥이고, 5번 등급은 대학원에 영혼을 바친 석박사 분들입니다. 역시 잔혹하게도 평균적으로 가방끈(교육 수준)이 길어질수록 월급은 수직 상승합니다.
We also have information regarding each employee’s education level and the year in which the wage was earned. 다행히 우리는 그 아저씨들의 나이뿐만 아니라 가방끈의 길이(교육 수준)와 대체 몇 년도에 그 돈을 벌었는지(타이밍 연도) 정보도 뒤 캐서 갖고 있습니다.
The center and right-hand panels of Figure 1.1, which display wage as a function of both year and education, indicate that both of these factors are associated with wage.
그림 1.1의 가운데(연도) 도화지와 오른쪽(학력) 도화지를 보세요. 이 두 가지 정보 역대급 스펙 요소들이 월급과 아주 지독하게 엮여(연관되어) 있다는 걸 팍팍 티 내고 있습니다.
Wages increase by approximately $10,000, in a roughly linear (or straight-line) fashion, between 2003 and 2009, though this rise is very slight relative to the variability in the data. 가운데 그림을 보면 2003년부터 2009년 사이 세월이 흐르며 평균 월급이 아주 뻣뻣한 일직선(선형) 모양으로 찔끔찔끔 올라서 한 1천만 원 남짓 오르긴 올랐습니다. (물론 위아래로 점들이 수백 개씩 날뛰는 분산 꼬라지를 보면 이깟 1천만 원 상승은 티도 안 나는 개미 콧구멍만 한 수준이긴 하지만요.)
Wages are also typically greater for individuals with higher education levels: men with the lowest education level (1) tend to have substantially lower wages than those with the highest education level (5). 오른쪽 그림을 보면 팩트 폭행이 더 심합니다. 가방끈이 긴 사람일수록 지갑이 터질 듯 뚱뚱해집니다. 고졸도 못한 그룹(1단계) 아재들은, 대학원에 영혼을 간 석박사 아재들(5단계) 발끝에도 못 미칠 만큼 실질적으로 끔찍하게 돈을 덜 받는 경향이 보이죠.
Clearly, the most accurate prediction of a given man’s wage will be obtained by combining his age, his education, and the year.
자, 머리가 있다면 답은 확실합니다! 어떤 아저씨의 월급을 진짜 소름 돋게 정확히 때려 맞추고(가장 정확한 예측) 싶다면, 꼴랑 나이 하나만 볼 게 아니라 그 사람의 가방끈과 동시 시대의 달력(연도)까지 모조리 한꺼번에 비빔밥처럼 비벼서 종합(결합)해야만 한다는 겁니다.
In Chapter 3, we discuss linear regression, which can be used to predict wage from this data set.
저기 뒷마당 3장에 가면 우리는 옛날 할아버지들이 발명하신 ‘선형 회귀(linear regression)’ 라는 기법을 배울 텐데, 바로 이 녀석이 눈앞의 아저씨 월급 예측에 신들린 듯 쓰일 무기입니다.
Ideally, we should predict wage in a way that accounts for the non-linear relationship between wage and age.
근데 이상적으로 치자면 우리 기계는 아까 나이 60에 훅 꺾이는 미끄럼틀(월급과 나이의 기괴한 비선형적 꺾임 관계)을 눈치채고 휘어지게 예측을 해줘야 진짜 똑똑한 로봇이죠.
In Chapter 7, we discuss a class of approaches for addressing this problem. 이런 꺾이는 곡선 따위의 짜증 나는 문제를 어떻게 깔끔하게 휘어잡는지는 머나먼 7장에 가서 썰을 풀겠습니다.
Stock Market Data (주식 시장 데이터: 내일의 삼전은 오를까 내릴까?)
The Wage data involves predicting a continuous or quantitative output value.
방금 본 아저씨 월급(Wage) 데이터 장난감은 “120만 원, 300만 원”처럼 쭉 이어지는 숫자로 된 돈(연속적인 정량적 출력)의 크기를 때려 맞추는 미션이었습니다.
This is often referred to as a regression problem. 이런 식으로 타겟이 숫자 크기면 우리는 고상하게 ‘회귀(Regression) 문제’ 라고 명명하죠.
However, in certain cases we may instead wish to predict a non-numerical value—that is, a categorical or qualitative output. 하지만 세상일이 다 숫자로 떨어지는 건 아닙니다. 가끔 우리는 이따위 숫자가 아니라, “개냐 고양이냐”, “남자냐 여자냐” 하는 찐 팀 고르기표(범주형이거나 질적인 이름표)를 예측하고 싶을 때가 있습니다.
For example, in Chapter 4 we examine a stock market data set that contains the daily movements in the Standard & Poor’s 500 (S&P) stock index over a 5-year period between 2001 and 2005. 예를 들자면, 4장에서는 피 말리는 주식 시장 데이터를 까볼 건데, 2001년부터 2005년까지 장장 5년간 묻어둔 월스트리트 S&P 500 주식들의 피 튀기는 매일매일의 변동 차트가 담겨있습니다.
We refer to this as the Smarket data.
이 끔찍한 주식판 장난감을 우리는 폼나게 Smarket 데이터라고 부릅니다.
The goal is to predict whether the index will increase or decrease on a given day, using the past 5 days’ percentage changes in the index. 우리의 헛된 목표(욕망)는 하나입니다. 이 주식이 과거 5일 동안 널뛰었던 힌트들을 로봇에게 욱여넣고, “내일 당장 이 주식이 위로 치솟을 거냐, 아래로 처박힐 거냐?”를 점쟁이처럼 예견하는 거죠!
Here the statistical learning problem does not involve predicting a numerical value. 잘 보세요, 이 판에서는 로봇 보고 “내일 주가가 12,300원일 거야!” 하고 숫자를 맞추라고 강요하지 않습니다.
Instead it involves predicting whether a given day’s stock market performance will fall into the Up bucket or the Down bucket.
대신 로봇이 해야 할 일은 내일 주식의 성적표가 빨간 불(상승, Up) 바구니로 골인할지 아니면 파란 불(하락, Down) 바구니로 처박힐지 딱 두 팀 중 하나로 찍어 넘기는(분류하는) 겁니다.
This is known as a classification problem. 그래서 우리는 이 바구니 넣기 게임을 전문 용어로 ‘분류(Classification) 문제’ 라고 통쾌하게 부릅니다.
A model that could accurately predict the direction in which the market will move would be very useful! 솔직히 말해서, 이 변덕스러운 시장이 위로 갈지 아래로 갈지 정확하게 찍어줄 수 있는 인공지능이 있다면 당장 집 팔아서 투자하고 빌딩 샀겠죠! 아주 개꿀(매우 유용)일 겁니다!
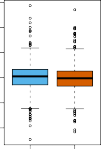
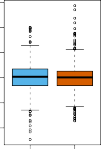
FIGURE 1.2. Left: Boxplots of the previous day’s percentage change in the S&P index for the days for which the market increased or decreased, obtained from the Smarket data. Center and Right: Same as left panel, but the percentage changes for 2 and 3 days previous are shown.
그림 1.2. (왼쪽 도화지): 주가가 오른 날(Up)과 처박힌 날(Down)을 갈라놓고, 그놈들이 전날 며칠이나 뛰었나(전날 지수 변동률) 비교해 본 상자 그림입니다. (가운데 & 오른쪽 도화지): 왼쪽이랑 붕어빵처럼 똑같은데 하루 전 대신 이틀 전, 삼일 전 변동률을 까본 겁니다.
The left-hand panel of Figure 1.2 displays two boxplots of the previous day’s percentage changes in the stock index: one for the 648 days for which the market increased on the subsequent day, and one for the 602 days for which the market decreased. 그림 1.2의 왼쪽 도화지가 뼈 때리는 현실을 보여줍니다. 기껏 주가가 떡상한 영광의 날들(648일)과 폭망한 피의 날들(602일) 두통의 데이터를 찢어 발겨 놨는데, 그 전날(어제)의 주가 변동 기록을 열어보니…
The two plots look almost identical, suggesting that there is no simple strategy for using yesterday’s movement in the S&P to predict today’s returns. 맙소사! 위아래 상자 두 개가 소름 돋게 그냥 쌍둥이처럼 완전히 붕어빵으로 똑같이 생겼습니다! 이 말인즉슨, 그냥 멍청하게 “어제 올랐으니 오늘도 오르겠지~” 같은 초딩 발상 전략으론 이 얼어 죽을 주가(수익률)를 거저먹을 방도가 전혀 없다는 쓰디쓴 절망을 암시하는 거죠.
The remaining panels, which display boxplots for the percentage changes 2 and 3 days previous to today, similarly indicate little association between past and present returns. 이틀 전, 삼일 전 차트를 열어 까서 그린 나머지 가운데랑 오른쪽 도화지도 마찬가지입니다. 과거 박스들과 오늘 수익률 사이에는 개미 눈곱만큼의 티끌만 한 연관성조차 도통 찾아볼 수가 없습니다.
Of course, this lack of pattern is to be expected: in the presence of strong correlations between successive days’ returns, one could adopt a simple trading strategy to generate profits from the market. 사실 이렇게 로또 번호 같이 아무 패턴(힌트)이 없는 개판 오분 전 상황이 주식 시장에선 당연한(예상된) 일입니다. 만약 주가 연속 날들 사이에 “어제 오르면 무조건 이틀 뒤에도 오른다” 급의 뻔한 연결고리가 있었다면, 개나 소나 그 단순한 법칙(트레이딩 전략)을 써서 시장 돈을 다 쪽쪽 빨아먹고 튀었겠죠!
Nevertheless, in Chapter 4, we explore these data using several different statistical learning methods. 하지만 우리가 누굽니까! 그런 뻔한 절망에도 불구하고, 머나먼 4장에 가면 우리는 기어코 기계들에게 온갖 통계 무기를 쥐여주고 이 주식 쓰레기 데이터를 어떻게든 요리(탐색)해 보려고 삽질을 할 겁니다.
Interestingly, there are hints of some weak trends in the data that suggest that, at least for this 5-year period, it is possible to correctly predict the direction of movement in the market approximately 60% of the time (Figure 1.3). 그런데 완전 대반전! 우리가 이 쓰레기를 미친 듯이 쥐어짜다 보니, 적어도 저 5년 동안만큼은 “오? 이렇게 하니까 기계가 10번 중 무려 6번(60%)이나 시장의 빨간불 파란불 방향을 정확하게 맞추네?” 라는 실낱같은 미라클 발악의 희망(약한 추세)을 발견하게 됩니다(그림 1.3 참조).

FIGURE 1.3. We fit a quadratic discriminant analysis model to the subset of the Smarket data corresponding to the 2001–2004 time period, and predicted the probability of a stock market decrease using the 2005 data. On average, the predicted probability of decrease is higher for the days in which the market does decrease. Based on these results, we are able to correctly predict the direction of movement in the market 60% of the time.
그림 1.3. (저희가 2001년부터 2004년 과거 데이터를 기계한테 먹이고 ‘이차 판별 분석 모델’이라는 좀 있어 보이는 무기를 만들었습니다. 그리고 아무런 정보 없는 2005년 미래 데이터를 들이밀며 하락 확률을 찍어보라고 했죠. 소름 돋게도 진짜 주식이 폭락한 날, 우리 로봇이 뱉은 하락 확률도 평균적으로 유의미하게 더 높았답니다. 덕분에 승률 60%짜리 점쟁이가 탄생했습니다!)
Gene Expression Data (유전자 발현 데이터: 넌 내 정답조차 안겨주지 않았지)
The previous two applications illustrate data sets with both input and output variables. 방금 구경한 월급이랑 주가 장난감들은 참 복 받은 문제들입니다. 왜냐면 “힌트(입력) 보고 이 답(출력)을 찍어!” 라고 명확하게 문제집과 해설지가 같이 붙어있었거든요.
However, another important class of problems involves situations in which we only observe input variables, with no corresponding output. 허나 인생은 실전! 통계판에서 가장 골 때리는 상황은 힌트는 산더미처럼 관찰해서 가져왔는데, “그래서 이게 뭔데?” 하고 맞춰야 할 진정한 타겟(출력 정답지)이 애초에 백지상태로 사라져 버린 미친 경우입니다.
For example, in a marketing setting, we might have demographic information for a number of current or potential customers. 쇼핑몰 마케팅 부서를 상상해 보세요. 사이트에 구경 온 수만 명 잠재 고객들의 딸깍질 클릭 나이, 동네, 장바구니 목록 같은 호구 조사 정보(힌트)는 진공청소기처럼 쫙 빨아들였습니다.
We may wish to understand which types of customers are similar to each other by grouping individuals according to their observed characteristics. 근데 당장 이 사람들한테 “당신은 부자! 당신은 구두쇠!”라고 적어놓은 정답지가 없으니, 우린 그냥 수만 마리 호구(고객)들의 특성을 이리저리 째려보다가 “어? 얘네 쇼핑하는 짓거리가 비슷한 거 같은데?” 하고 이놈들을 그저 몇 개의 파벌(그룹)로 묶어서(군집화) 이해하고 싶은 소박한 소망이 생기죠.
This is known as a clustering problem. 우리는 이 끼리끼리 묶어서 노는 작업을 통계쟁이들 은어로 ‘클러스터링(Clustering, 패거리 짜기)’ 문제라고 통칭합니다.
Unlike in the previous examples, here we are not trying to predict an output variable. 앞서 돈 냄새나는 예제들과는 뼛속부터 확연히 다르게, 여기서는 뭔가 특정한 미래의 떡상 정답값을 “맞추겠다(예측)!”는 부푼 꿈과 욕심을 철저히 버렸습니다.
We devote Chapter 12 to a discussion of statistical learning methods for problems in which no natural output variable is available. 이 정답지 잃어버린 불쌍한 분석가들의 방황(비지도 학습)을 구원하기 위해, 우리는 까마득히 저 먼 미래 12장에 거대한 굿판을 벌여 치열한 논의를 할애했습니다.
We consider the NCI60 data set, which consists of 6,830 gene expression measurements for each of 64 cancer cell lines.
이번 장난감 스케일 좀 보실까요? 64명의 불쌍한 암 환자 피(세포주)를 뽑아서 조각조각 쪼갰더니, 무려 6,830개나 되는 우글우글한 미세 유전자 발현 힌트 수치들이 가득 찬 끔찍한 NCI60 유전자 데이터셋입니다.
Instead of predicting a particular output variable, we are interested in determining whether there are groups, or clusters, among the cell lines based on their gene expression measurements. 이 수만 개의 숫자로 “이 사람이 내일 죽을까 살까?”(타겟 예측)를 맞추려는 얄팍한 목표 따윈 접어두고, 우린 이 64개의 각기 다른 세포 덩어리들이 뿜어내는 6,830개의 신호들을 킁킁 맡으면서 “어라? 이 지독한 세포들 사이에서도 끼리끼리 은밀하게 뭉쳐 노는 은하계 파벌(클러스터 파벌)이 존재할까?”를 냄새 맡고 파헤치는 데 혈안이 되어 있습니다.
This is a difficult question to address, in part because there are thousands of gene expression measurements per cell line, making it hard to visualize the data. 솔직히 이거 대답하기 진짜 토 나오는 헬 난이도 문제입니다. 세포 한 개당 무려 6,830개나 되는 숫자 폭탄 힌트가 엉켜 있다 보니, 이걸 우리 닝겐의 눈알로 보게 3차원 허공(시각화)에 점으로 예쁘게 띄울 방법이 아예 없기 때문이죠. 눈이 6,830개가 달려있지 않는 한 말입니다!
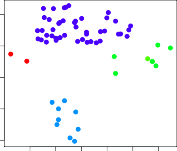
FIGURE 1.4. Left: Representation of the NCI60 gene expression data set in a two-dimensional space, $Z_1$ and $Z_2$. Each point corresponds to one of the 64 cell lines. There appear to be four groups of cell lines, which we have represented using different colors. Right: Same as left panel except that we have represented each of the 14 different types of cancer using a different colored symbol. Cell lines corresponding to the same cancer type tend to be nearby in the two-dimensional space.
그림 1.4. (왼쪽 도화지): 우리가 마법(차원 축소)을 부려서 6,830개 숫자를 딱 두 개($Z_1, Z_2$)로 찌그러트린 뒤 도화지에 세포 64마리를 찍어봤습니다. 허공을 헤매다 그들끼리 네 갈래 파벌(그룹)로 옹기종기 뭉친 꼬라지가 보여서 친절하게 4원색으로 칠해줬죠. (오른쪽 도화지): 충격 반전! 그 점들에다가 실제 그 세포가 무슨 암(14종류)이었는지 정답 스킨 기호를 씌워본 겁니다. 기가 막히게도 같은 종류의 암 녀석들이 공간에서 지들끼리 찰싹 붙어서 놀고 있는 경향이 포착됐습니다.
The left-hand panel of Figure 1.4 addresses this problem by representing each of the 64 cell lines using just two numbers, $Z_1$ and $Z_2$. 그래서 그림 1.4 왼쪽 도화지에선 인간의 꼼수를 부렸습니다. 그 미친 6,830개의 숫자를 기적의 압축기계에 때려 넣고 확 짓이겨버려서, 오직 x축($Z_1$)과 y축($Z_2$) 단 두 개의 숫자표로만 64개 세포를 아담하게 표현해 냈습니다!
These are the first two principal components of the data, which summarize the 6,830 expression measurements for each cell line down to two numbers or dimensions. 이 압축기의 정체를 나중에 배울 텐데, 6,830개의 더러운 수치들을 뼈다귀의 진국만 쭉 뽑아서 두 개의 엑기스 숫자(2차원 통계)로 요약해 버린 이걸 ‘주성분(Principal components)’ 이라고 부릅니다.
While it is likely that this dimension reduction has resulted in some loss of information, it is now possible to visually examine the data for evidence of clustering. 물론 6,830개를 고작 2개로 무자비하게 박살 냈으니 엄청난 정보증발 손실이 있었겠지만, 무슨 상관입니까? 이제 우리 인간의 눈알로 직접 도화지를 째려보고 “옿! 저기 끼리끼리 뭉친 흔적(증거)이 있네!” 하고 눈으로 시각적 분석이 가능한 세상이 열렸는데요!
Deciding on the number of clusters is often a difficult problem. 근데 솔직히 저 점들이 과연 3파벌인지, 4파벌인지 애매하게 엉켜있어서 “이게 몇 등분이야?” 하고 확정(클러스터 수 결정) 짓는 건 늘 뒤통수가 얼얼한 어려운 일입니다.
But the left-hand panel of Figure 1.4 suggests at least four groups of cell lines, which we have represented using separate colors. 그래도 우리가 볼 땐 그림 1.4의 왼쪽에 얼추 세포들이 ‘최소 4개 파벌(그룹)’ 정도로는 쪼개지고 뭉친 거 같아서, 조물주가 빙의하여 다르게 색깔 4개를 입혀 줘 봤습니다.
In this particular data set, it turns out that the cell lines correspond to 14 different types of cancer. 근데 대반전! 의사 선생님한테 뒷돈 주고 장부를 까보니까, 이 실험판에 쓰인 세포들은 원래 사실 14가지나 되는 서로 다른 아주 더러운 암 녀석들이었던 겁니다(정답 공개)!
(However, this information was not used to create the left-hand panel of Figure 1.4.) (물론 우리가 왼쪽 그림에서 4파벌로 예쁘게 색칠 놀이할 때, 저 정답(암 정보) 따위는 절대 안 보고 손발 묶고 찍은 겁니다!)
The right-hand panel of Figure 1.4 is identical to the left-hand panel, except that the 14 cancer types are shown using distinct colored symbols. 그럼 진실의 오른쪽 그림 1.4 도화지를 보실까요? 왼쪽이랑 위치는 똑같은데, 다만 각 세포들의 점 모양을 ‘진짜 14개 암 종류 스킨(심볼)’으로 바꿔서 확 다르게 색칠해 입힌 버전입니다.
There is clear evidence that cell lines with the same cancer type tend to be located near each other in this two-dimensional representation. 결과는 충격적입니다! 2차원 허공에 아무렇게나 뿌려놓은 점들이었는데, 딱 껍질(피아식별자)을 벗겨보니 맙소사 같은 종류의 징글징글한 암세포들끼리 서로 동네방네 찰싹찰싹 들러붙어(가까이 위치) 모여 살고 있다는 소름 돋는 명백한 증거가 발견된 겁니다!
In addition, even though the cancer information was not used to produce the left-hand panel, the clustering obtained does bear some resemblance to some of the actual cancer types observed in the right-hand panel. 이게 왜 쩌는 거냐고요? 우리가 왼쪽 도화지를 찢어 발길 땐 암 종류(정답 힌트) 따윈 하나도 안 썼는데, 기계가 끼리끼리 분류해 낸 그 모양새(얻은 클러스터링)가, 오른쪽의 실제 팩트(현실의 진짜 암 종류 그룹)랑 놀랍도록 소름 돋게 비슷한 형상(유사함)을 띠고 있다는 점입니다!
This provides some independent verification of the accuracy of our clustering analysis. 이 위대한 발견 덕분에 우린 허공에 주먹질한 “아무 정보 없이 때려 맞추는 파벌 나누기 기술(우리의 클러스터링 분석)”이 진짜 현실 세계에서도 먹힌다는 걸, 누구 도움 없이 독고다이(독립적)로 증명하고 정확도가 쓸만하다는 걸 확인(검증)받는 쾌거를 이루게 됐습니다!
Sub-Chapters (하위 목차)
| < 1. Introduction | 1.2 A Brief History Of Statistical Learning > |