| < 2. Statistical Learning | 2.1.1 Why Estimate F > |
💡 학습 팁: 조금 더 쉽고 재미있게 공부하고 싶으신가요? 이 페이지는 중학생도 이해할 수 있는 친절한 ‘쉬운 해설판’입니다! 영어 원문을 문장 단위로 꼼꼼하게 번역한 느낌을 원하신다면 📖 직역본 보기 메뉴를 활용하세요!
2.1 What Is Statistical Learning?
2.1 통계적 학습이란 무엇인가? (입력 버튼과 출력 자판기)
In order to motivate our study of statistical learning, we begin with a simple example. 이 ‘통계적 학습’이라는 골치 아픈 수학 덩어리를 우리가 왜 구태여 배워야 하는지 뽐뿌(동기 부여)를 팍팍 넣기 위해, 아주 흔하고 만만한 예시 하나를 들고 시작하겠습니다.
Suppose that we are statistical consultants hired by a client to investigate the association between advertising and sales of a particular product. 여러분이 프리랜서 데이터 마법사(컨설턴트)라고 상상해보세요. 방금 어느 회사 사장님(클라이언트)이 수표를 턱 내밀며 “우리 회사 광고비랑 물건 매출액 사이에 무슨 끈적한 관계가 있는지 당장 조사해 봐!” 하면서 여러분을 고용한 겁니다.
The Advertising data set consists of the sales of that product in 200 different markets, along with advertising budgets for the product in each of those markets for three different media: TV , radio , and newspaper .
사장님이 쥐여준 Advertising(광고) 장부에는 장장 200곳이나 되는 각기 다른 동네 시장들의 물건 판매량(sales) 이 적혀있습니다. 그리고 그 200개 동네마다 돈을 얼마나 퍼부었는지 세 가지 매체별로 TV, 라디오(radio), 신문(newspaper) 광고비 내역이 꼼꼼하게 쓰여 있죠.
The data are displayed in Figure 2.1. 이 복잡한 숫자 장부를 그림 2.1에다 알아보기 쉽게 도화지로 옮겨 그린 겁니다.
It is not possible for our client to directly increase sales of the product. 상식적으로 생각해보세요. 사장님이 아무리 악을 쓰고 기도한다고 해서, 손님들의 지갑을 초능력으로 열어 물건 판매량 자체를 물리적으로 강제 떡상시키는 건 불가능합니다.
On the other hand, they can control the advertising expenditure in each of the three media. 하지만 그 반대쪽, 즉 세 가지 매체에 돈(광고비)을 얼마나 쏟아부을지 그 예산 밸브를 돌리며 통제하는 건 사장님 마음대로 할 수 있죠.
Therefore, if we determine that there is an association between advertising and sales, then we can instruct our client to adjust advertising budgets, thereby indirectly increasing sales. 그러니까 우리가 만약 “사장님, TV 광고비에 돈을 태울 때마다 매출이 미친 듯이 오릅니다!” 라는 꿀 연관성을 찾아낸다면? 사장님한테 그쪽으로 돈을 몰빵하라고 지시해서 간접적으로 매출을 떡상시켜버릴 수 있는 겁니다!
In other words, our goal is to develop an accurate model that can be used to predict sales on the basis of the three media budgets. 다시 말해 우리 마법사들의 진짜 임무는, “TV, 라디오, 신문 예산(힌트)이 이만큼이면, 매출(결과)은 요만큼 나올걸?” 하고 정확하게 점쟁이처럼 예언해 내는 튼튼한 계산기(모델)를 발명하는 것입니다.
In this setting, the advertising budgets are input variables while sales is an output variable .
이렇게 세팅해 놓고 보면, 우리가 집어넣는 광고 예산 금액들은 자판기 동전 같은 입력 변수(input variables) 들이고, 툭 떨어지는 sales(매출) 캔 음료수는 출력 변수(output variable) 가 되는 겁니다.
The input variables are typically denoted using the variable symbol X , with a subscript to distinguish them. 보통 이 동전(입력 힌트)들을 부를 때, 통계 동네에선 알파벳 $X$ 에다가 꼬리표(아래첨자)를 덕지덕지 붙여서 구별해 부르는 걸 좋아합니다.
So $X_1$ might be the TV budget, $X_2$ the radio budget, and $X_3$ the newspaper budget.
그래서 “1번 힌트 $X_1$은 TV 광고비, 2번 $X_2$는 라디오 광고비, 3번 $X_3$는 신문 광고비야” 이렇게 이름을 붙여주는 거죠.
The input variables go by different names, such as predictors , independent variables , features , or sometimes just variables . 참고로 이 자판기 동전(입력 변수) 녀석들은 부르는 사람 맘대로 이름표가 수십 개나 됩니다. 어떤 학자는 예측 변수(predictors), 누구는 수학책처럼 독립 변수(independent variables), AI쟁이들은 특징(features), 귀찮으면 그냥 뭉뚱그려 변수(variables) 라고 부릅니다. 헷갈리지 마세요!
The output variable—in this case, sales —is often called the response or dependent variable , and is typically denoted using the symbol Y .
반대로 자판기에서 튀어나오는 결과 캔(출력 변수), 여기서 치면 매출 같은 녀석들은 응답(response), 자기가 혼자 못 변하고 힌트에 기대서 변한다고 해서 종속 변수(dependent variable) 라고 부릅니다. 기호로는 보통 알파벳 대장 $Y$ 라고 폼나게 적어줍니다.
Throughout this book, we will use all of these terms interchangeably. 앞으로 이 두꺼운 책을 넘길 때마다 저 수많은 별명들을 엿장수 마음대로 번갈아 가며 막 쓸 거니까, 당황하지 말고 알아서 찰떡같이 “아, 입력 힌트! 아, 출력 결과!” 하고 알아먹어야 합니다.
More generally, suppose that we observe a quantitative response Y and p different predictors, $X_1, X_2, . . . , X_p$. 자, 시야를 팍 넓혀볼까요? 우리가 맞춰야 할 구체적인 숫자 정답(반응) 고래 1마리를 $Y$ 라 하고, 그걸 맞추기 위해 던지는 그물(예측 힌트들)이 무려 $p$ 개($X_1, X_2, \dots , X_p$)나 널려있다고 상상해 봅시다.
We assume that there is some relationship between Y and $X = (X_1, X_2, . . . , X_p)$, which can be written in the very general form 여기서 핵심은 정답 고래 $Y$ 랑 그물 힌트 뭉치 $X$ 들 사이에 ‘미지의 어떤 끈끈한 공식(연관성)’이 묶여있다고 강하게 믿어 의심치 않는 겁니다. 그걸 수학 공식으로 쓰면 아주 상식적인 이 모양이 나옵니다.
\[Y = f(X) + \epsilon \tag{2.1}\]
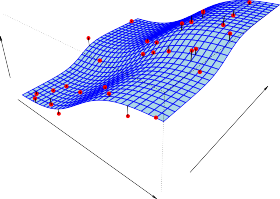
FIGURE 2.1. The Advertising data set. The plot displays sales , in thousands of units, as a function of TV , radio , and newspaper budgets, in thousands of dollars, for 200 different markets. In each plot we show the simple least squares fit of sales to that variable, as described in Chapter 3. In other words, each blue line represents a simple model that can be used to predict sales using TV , radio , and newspaper , respectively.
그림 2.1. Advertising(광고) 장부를 털어 그린 그림입니다. 각 동네(200곳)에서 TV, 라디오, 신문 예산을 얼마나 부었냐에 따라 매출 캔이 얼마나 터졌는지 점을 찍었죠. 각 도화지의 파란 직선은 “이 힌트로 매출을 맞춘다면 대충 이 선을 따라가겠네?” 하고 3장에서 배울 가장 멍청하고 단순한 오차 줄이기 곡선(최소 제곱 적합)을 하나 쓱 그어본 겁니다.
Here f is some fixed but unknown function of $X_1, . . . , X_p$ , and ϵ is a random error term , which is independent of X and has mean zero. 방금 본 식 $Y = f(X) + \epsilon$ 에서 주인공인 $f$ 가 바로 힌트 뭉치를 넣으면 정답을 튀어나오게 조리해 주는 ‘우주 어딘가에 존재하지만 우리 인간은 절대 볼 수 없는 완벽한 진리의 함수(마법 공식)’ 입니다. 그리고 뒤에 붙은 찌꺼기 $\epsilon$ (입실론)은 운이 나빠서 혹은 측정 기계가 덜덜 떨려서 우연히 잡음이 낀 ‘오차 항(error term)’ 이죠. 이 찌꺼기들의 평균을 다 합치면 0으로 상쇄된다고 봅니다.
In this formulation, f represents the systematic information that X provides about Y . 이 공식에서 마법의 함수 $f$ 라는 녀석은 힌트($X$)들이 똘똘 뭉쳐서 정답($Y$)에게 건네주는 ‘변치 않는 진짜 패턴(체계적인 정보)’ 만을 순도 100%로 쏙 뽑아낸 엑기스 덩어리 역할을 합니다.
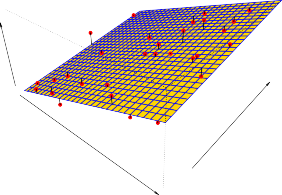
FIGURE 2.2. The Income data set. Left: The red dots are the observed values of income (in thousands of dollars) and years of education for 30 individuals. Right: The blue curve represents the true underlying relationship between income and years of education , which is generally unknown (but is known in this case because the data were simulated). The black lines represent the error associated with each observation. Note that some errors are positive (if an observation lies above the blue curve) and some are negative (if an observation lies below the curve). Overall, these errors have approximately mean zero.
그림 2.2. 이번엔 Income(수입) 장부입니다. 왼쪽 도화지를 보세요. 뻘건 점들은 세상 사람 30명을 붙잡아서 “가방끈 몇 년이나 길어? 월급 얼마 받아?” 하고 찍어놓은 진짜 현실 데이터입니다. 오른쪽 그림에 구불거리는 파란 선은 사실 인간은 절대 알 수 없는 우주의 진리인 완벽한 정답 곡선, 즉 마법 함수 $f$ 입니다 (이 데이터는 진짜가 아니라 우리가 시뮬레이션으로 조작해서 만든 거라 파란 선의 실체를 우리가 훔쳐볼 수 있는 겁니다). 그리고 점마다 파란 선에 못 미치고 위아래로 그어진 검은 막대기들이 보이시죠? 저게 바로 진리의 선을 벗어난 재수 없는 ‘운빨(오차, $\epsilon$)’입니다.
As another example, consider the left-hand panel of Figure 2.2, a plot of income versus years of education for 30 individuals in the Income data set.
이해를 돕기 위해 아까 그림 2.2 왼쪽 창문, 즉 30명의 ‘가방끈(교육 년수)’ 힌트 대 ‘돈줄(월급)’ 정답을 찍어본 상황을 다시 떠올려봅시다.
The plot suggests that one might be able to predict income using years of education.
가만 보니 가방끈이 길어질수록 돈줄 점들이 슬금슬금 우상향하는 꼴을 보아 무조건 가방끈($X$)으로 월급($Y$)을 꽤 그럴싸하게 찍어 맞출(예측) 수 있을 거란 냄새가 풀풀 납니다.
However, the function f that connects the input variable to the output variable is in general unknown. 하지만 아까 말했듯이 현실 세계에서 힌트와 정답을 완벽하게 이어주는 절대 반지 같은 함수 공식 $f$ 는 그 누구도 절대로 알 수 없이 꽁꽁 감춰져 있습니다. 조물주만이 아시겠죠.
In this situation one must estimate f based on the observed points. 결국 이 갑갑한 캄캄한 방 안에서, 우리 범상한 인간들이 할 수 있는 유일한 짓은 그저 관찰된 몇 개의 불빛(데이터 점)들만 더듬더듬 만져가며 “아마 미지의 공식 $f$ 는 대충 이렇게 생겨 먹었지 않았을까?” 하고 우리가 직접 가짜 야매 공식(추정치)을 만들어서 때려 맞추는 것뿐입니다.
Since Income is a simulated data set, f is known and is shown by the blue curve in the right-hand panel of Figure 2.2.
다행히 이 Income(수입) 장부는 우리가 방 안에서 몰래 뚝딱뚝딱 조작한 가짜 장부(시뮬레이션 데이터)라서, 신만이 안다는 진짜 진리 함수 $f$ 의 모습(파란색 곡선)을 살짝 커닝해서 오른쪽 그림에 그릴 수 있었습니다.
The vertical lines represent the error terms ϵ . 그리고 점들과 저 파란 진리의 선 사이를 잇는 얇은 위아래 수직 꼬챙이들이, 바로 아까 말했던 억울한 잡음 찌꺼기(운빨 오차 항, ϵ) 녀석들입니다.
We note that some of the 30 observations lie above the blue curve and some lie below it; overall, the errors have approximately mean zero. 30개의 점들을 가만히 째려보면 어떤 놈들은 파란 진리선 위에서 기고만장하고, 어떤 놈들은 아래에 처박혀 울고 있죠? 하지만 이걸 죄다 그러모아 평균을 내보면, 위아래로 팽팽하게 줄다리기하며 대충 0 근처에서 허무하게 사라진다는 걸 깨달을 수 있습니다.
In general, the function f may involve more than one input variable. 지금까진 힌트가 1개뿐이었지만, 여러분도 알다시피 세상사가 그렇게 만만합니까? 보통 진리의 함수 f 에 들어가는 자판기 동전(힌트 입력 변수)은 무조건 여러 개가 섞여 들어갑니다.
In Figure 2.3 we plot income as a function of years of education and seniority .
그래서 그림 2.3(책 뒤쪽)에는 아예 판을 더 벌려서, ‘가방끈(교육)’ 뿐만 아니라 ‘짬바(연공서열)’ 힌트 두 개를 던져주고 아저씨의 지갑 두께(수입)를 맞추는 무대를 깔아봤습니다.
Here f is a two-dimensional surface that must be estimated based on the observed data. 힌트가 두 개가 되면 선이 아니고, 허공에 둥둥 떠 있는 구불구불한 돗자리 형태의 ‘2차원 곡면’이 나타납니다. 우리는 이제 관찰된 점들을 보고 이 거대한 돗자리 표면(함수 f)을 머리 터지게 더듬어 추정해야만 하죠.
In essence, statistical learning refers to a set of approaches for estimating f . 한 줄로 요약하겠습니다. ‘통계적 학습(Statistical Learning)’ 이란 이 빌어먹을 조물주의 절대 함수 f 돗자리를 인간의 얄팍한 두뇌로 어떻게든 아주 비슷하게 베끼고 때려 맞춰보려는 발악적인 기법들의 총집합을 폼나게 부르는 말입니다.
In this chapter we outline some of the key theoretical concepts that arise in estimating f , as well as tools for evaluating the estimates obtained. 자, 이 웅장한 2장에서 우리는 이 미지의 돗자리 f 를 베끼다가 생기는 치명적인 딜레마(이론적 개념들)를 파헤치고, 우리가 만든 그 짝퉁 $f$ 돗자리가 진품이랑 얼마나 똑같은지 감정을 매겨주는(평가) 도구들에 대해서도 한 수레 풀어놓을 예정입니다.
2.1.1 Why Estimate f ? (왜 f를 추정해야 하는가?)
우리가 함수 $f$를 미치도록 찾고 싶어 하는 두 가지 이유, 즉 내일 당장 얼마를 벌지 ‘점쟁이처럼 맞추는 예측(Prediction)’과 도대체 왜 이런 일이 터졌는지 ‘명탐정처럼 범인을 색출하는 추론(Inference)’의 개념을 다룹니다.
2.1.2 How Do We Estimate f ? (어떻게 f를 추정하는가?)
과거 오답 노트(학습 데이터)를 가지고 기계가 어떻게 수학 공식을 빚어내는지 작동 원리를 까발립니다. 특히 공식을 딱 각 잡고 정해놓는 파라미터(Parametric) 모델과 프리스타일로 그려내는 비파라미터 모델의 치고받는 대결을 관전합니다.
2.1.3 The Trade-Off Between Prediction Accuracy and Model Interpretability (정확도 vs 설명력의 딜레마)
기계가 기가 막히게 과녁은 잘 맞추는데 안에서 뭔 짓거리를 하는지 도통 설명이 안 되는 답답한 ‘블랙박스’ 현상을 파헤칩니다. 내가 정확함이 필요한지, 아니면 사장님께 바칠 변명(해석)이 필요한지 딜레마 속에서 줄타기하는 법을 기릅니다.
2.1.4 Supervised Versus Unsupervised Learning (과외 선생님 유무의 차이)
과외 선생님이 옆에 착 붙어 완벽한 해설지(정답)를 먹여주며 키우는 ‘지도 학습’ 방과, 정답을 뺏고 애들끼리 눈치껏 파벌을 짜게 던져두는 ‘비지도 학습’ 방의 눈물겨운 차이점을 비교합니다. 곁다리로 반반 무 많이 같은 ‘반지도 학습’도 슬쩍 맛봅니다.
2.1.5 Regression Versus Classification Problems (숫자 맞추기 vs 바구니 꽂기)
맞춰야 할 정답이 월급이나 집값처럼 끝없이 이어진 구체적인 숫자 게임(회귀)인지, 아니면 합격/불합격처럼 꼬리표 바구니에 던져넣는 분류 게임(Cllassification)인지 갈라치고, 방이 다르면 써야 하는 무기도 완전 달라진다는 걸 배웁니다.
Sub-Chapters (하위 목차)
| < 2. Statistical Learning | 2.1.1 Why Estimate F > |